

{kind=link}
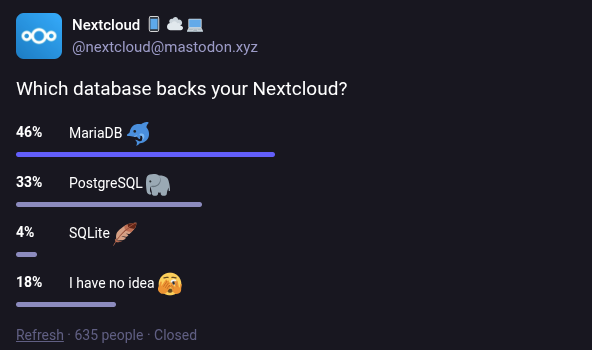
Nextcloud asked in a poll at https://mastodon.social/@nextcloud@mastodon.xyz/115095096413238457 what database its users are running. Interestingly one fifth replied they don’t know. Should people know better where their data is stored, or is it a good thing everything is running so smoothly people don’t need to know what their software stack is built upon?
Self hosting doesn’t mean “being wasteful and letting containers duplicate services”. I want to know which DB application X is using, so I pool it for applications Y and Z.
For most applications the overhead of running a second DB server is negligible.
I disagree. You are just entertaining the idea that servers must always and forever be oversized, that’s the definition of wasteful (and environmentally irresponsible). Unless you are firing-up and throwing-away services constantly, nothing justifies this and sparing the relatively low effort it is to deploy your infrastructure knowingly.
Do you have the data to back that up? Have you measured how much of an impact on system load and power consumption having 2 separate DB processes has?
Roughly the same amount of work is being done by the CPU if you split your DBs between 2 servers or just use one. There might be a slight increase in memory usage, but that would only matter in a few niche applications and wouldn’t affect environmental impact.
I mean, you are the one making the exceptional claim that unnecessarily running multiple instances of programs on a device with finite resources has no practical adverse effect. Of course, the effects can be more or less drastic depending on the many variables at play (hardware, software, memory pressure, thread starvation, cache misses, …) and can indeed be negligible in some lucky circumstances. The point is that you don’t call that shot, and especially not by burying your head in the sand and pretending it’s never gonna be a problem.
Effective use of computing resources requires tuning. Introduction of a new service creates imbalance. Ensuring that the server performs nominally and predictably for all intended services is a balancing act and a sysadmin’s job. Services whose deployment settings are set by someone with no prior knowledge of the deployment constraints can’t be trusted to do a good job at it (that’s the nature of the physical world we live in, not my opinion), and promoting this attitude promote the kind of wasteful and irresponsible computing I was on about.
Now, I’ll give you the link to this basic helper for tuning a PostgreSQL server: https://pgtune.leopard.in.ua/
Will you tell me what are the correct inputs for my homelab (I won’t tell you the hardware, the set-up, the other services running on it, the state of the system, etc)?
And later, when you will distribute your successful container to millions of users, what will you respond to the angry ones that will complain that your software is slow, to no fault of your coding, because they happen to pile up multiple DBs, web servers, application servers, reverse proxies, … on their banana SoCs?
I’m saying this based on real world experience: after a certain point you start to see deminishing returns when optimizing a system, and you’re better off focusing your efforts elsewhere. For most applications, customizing containerized services to share databases is far past that point.
And if it’s SQLite (which I believe is the default) it’s really just reading and writing a file on the file system.
This is one of my pet peeves with containerized services, like why would I want to run three or four instances of mariadb? I get it, from the perspective of the packagers, who want a ‘just works’ solution to distribute, but if I’m trying to run simple services on a 4 GB RPi or a 2 GB VPS, then replicating dbs makes a difference. It took a while, but I did, eventually, get those dockers configured to use a single db backend, but I feel like that completely negated the ‘easy to set up and maintain’ rationale for containers.
Precisely what pre-devops sysadmins were saying when containers were becoming trendy. You are just pushing the complexity elsewhere, and creating novel classes of problems for yourself (keeping your BoM in control and minimal is one of many others that got thrown away)